
零基础写python爬虫之爬虫编写全记录
先来说一下我们学校的网站:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html
查询成绩需要登录,然后显示各学科成绩,但是只显示成绩而没有绩点,也就是加权平均分。
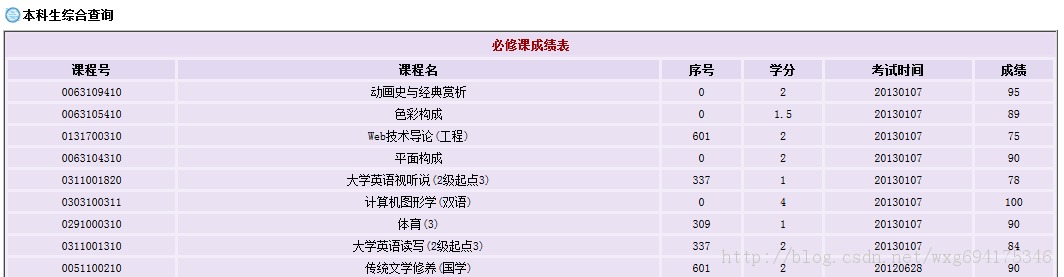
显然这样手动计算绩点是一件非常麻烦的事情。所以我们可以用python做一个爬虫来解决这个问题。
1.决战前夜
先来准备一下工具:HttpFox插件。
这是一款http协议分析插件,分析页面请求和响应的时间、内容、以及浏览器用到的COOKIE等。
以我为例,安装在火狐上即可,效果如图: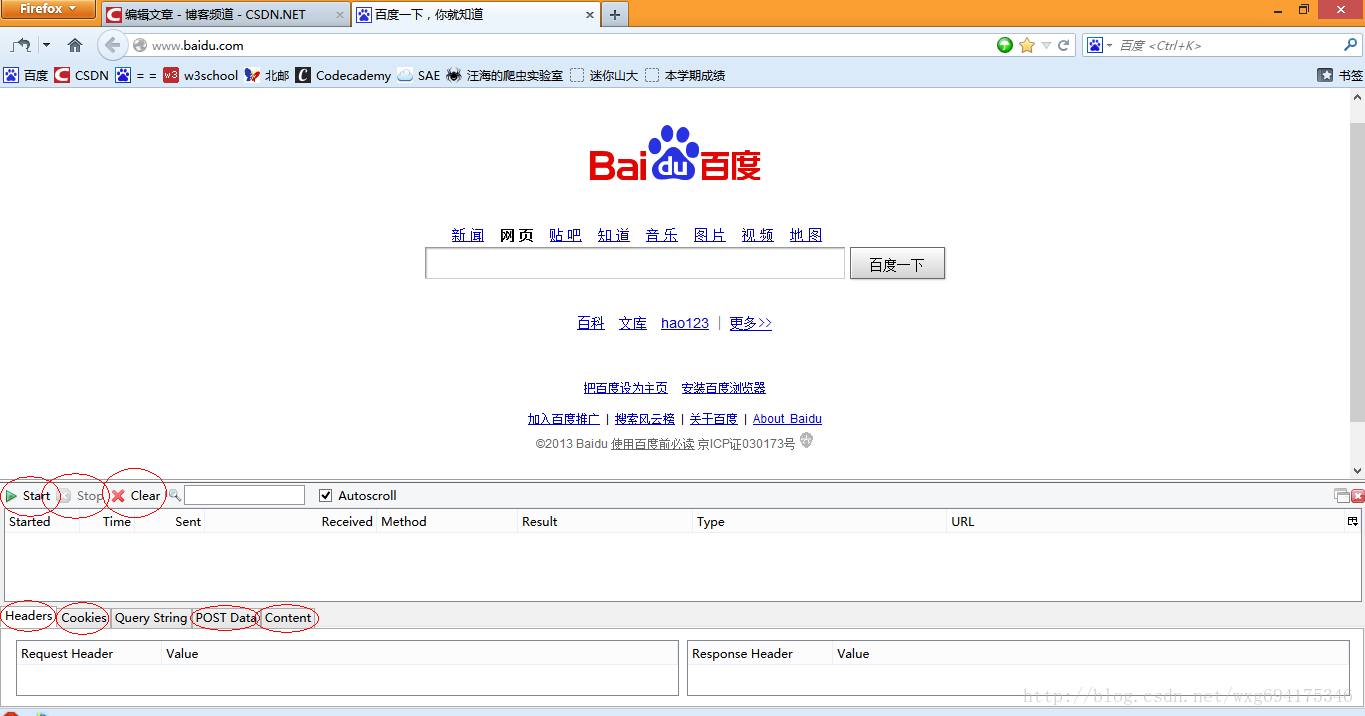
可以非常直观的查看相应的信息。
点击start是开始检测,点击stop暂停检测,点击clear清除内容。
一般在使用之前,点击stop暂停,然后点击clear清屏,确保看到的是访问当前页面获得的数据。
2.深入敌后
下面就去山东大学的成绩查询网站,看一看在登录的时候,到底发送了那些信息。
先来到登录页面,把httpfox打开,clear之后,点击start开启检测:
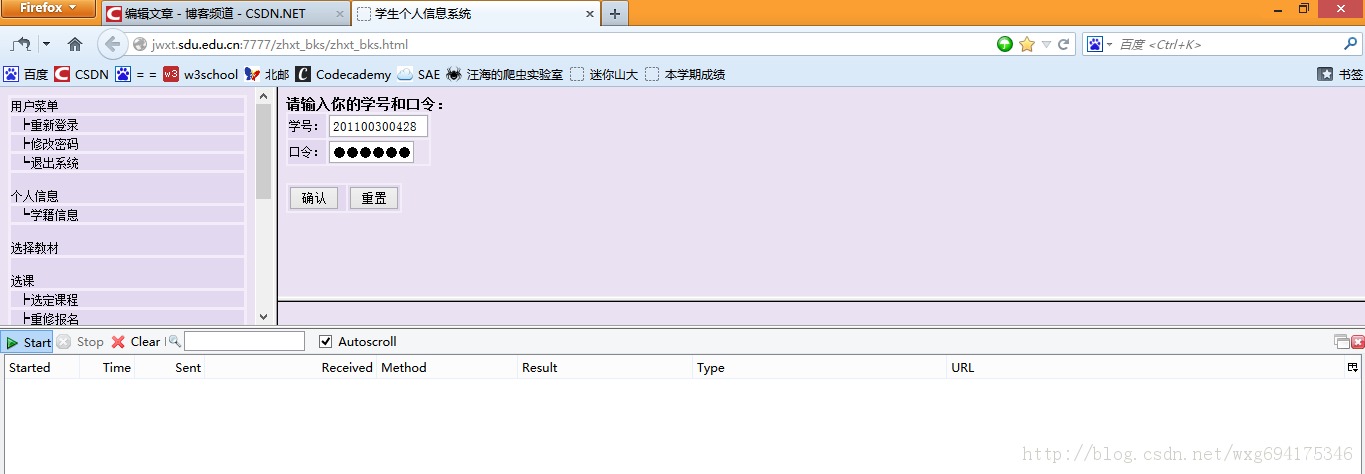
输入完了个人信息,确保httpfox处于开启状态,然后点击确定提交信息,实现登录。
这个时候可以看到,httpfox检测到了三条信息:
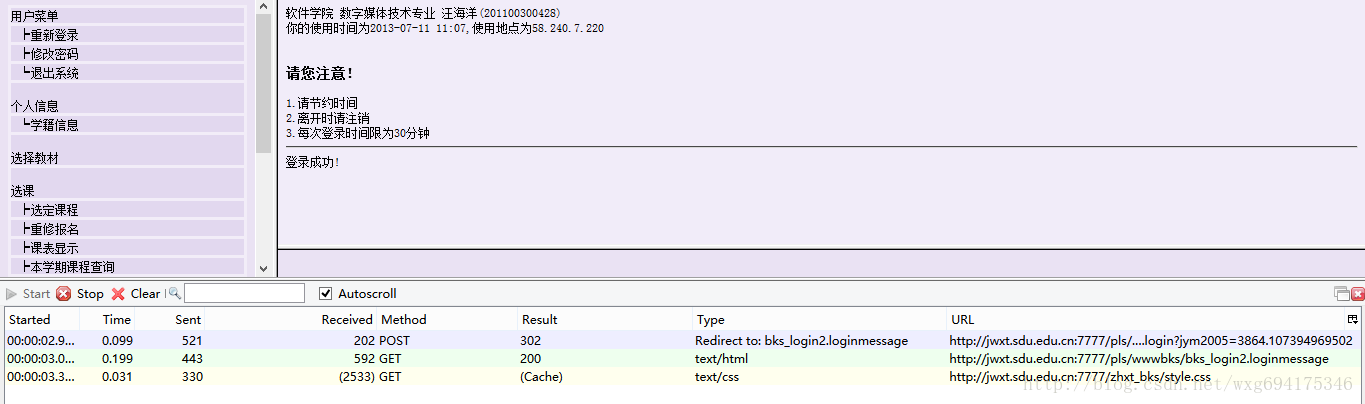
这时点击stop键,确保捕获到的是访问该页面之后反馈的数据,以便我们做爬虫的时候模拟登陆使用。
3.庖丁解牛
乍一看我们拿到了三个数据,两个是GET的一个是POST的,但是它们到底是什么,应该怎么用,我们还一无所知。
所以,我们需要挨个查看一下捕获到的内容。
先看POST的信息:
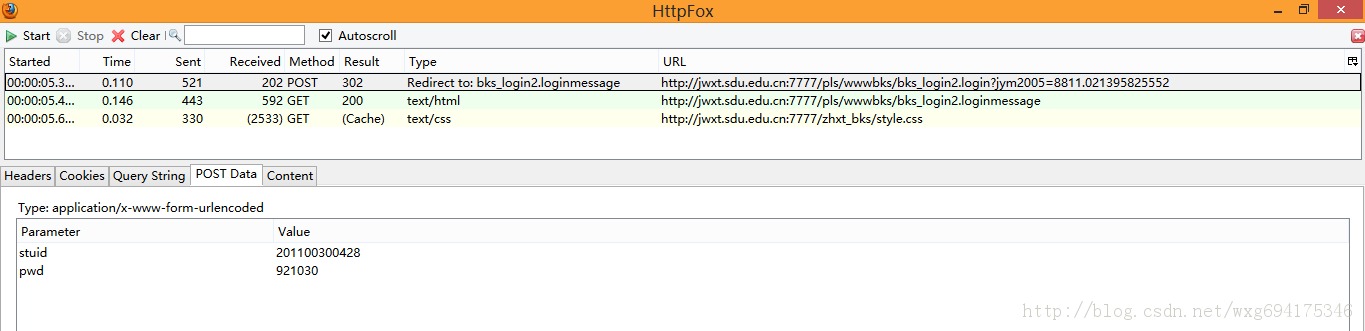
既然是POST的信息,我们就直接看PostData即可。
可以看到一共POST两个数据,stuid和pwd。
并且从Type的Redirect to可以看出,POST完毕之后跳转到了bks_login2.loginmessage页面。
由此看出,这个数据是点击确定之后提交的表单数据。
点击cookie标签,看看cookie信息:
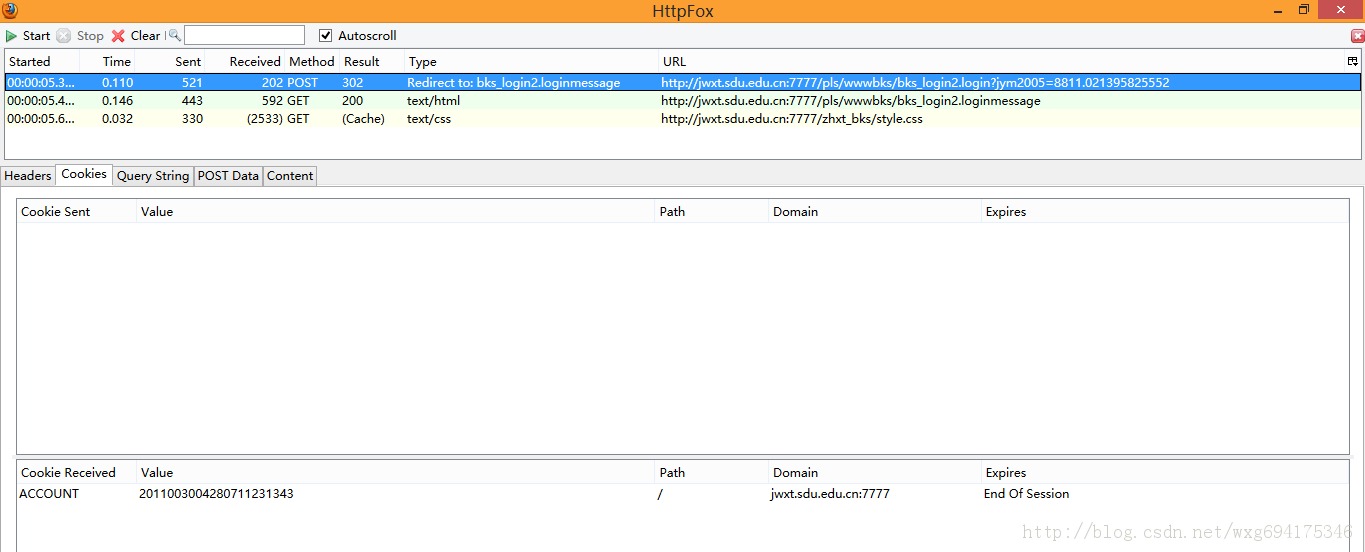
没错,收到了一个ACCOUNT的cookie,并且在session结束之后自动销毁。
那么提交之后收到了哪些信息呢?
我们来看看后面的两个GET数据。
先看第一个,我们点击content标签可以查看收到的内容,是不是有一种生吞活剥的快感-。-HTML源码暴露无疑了:
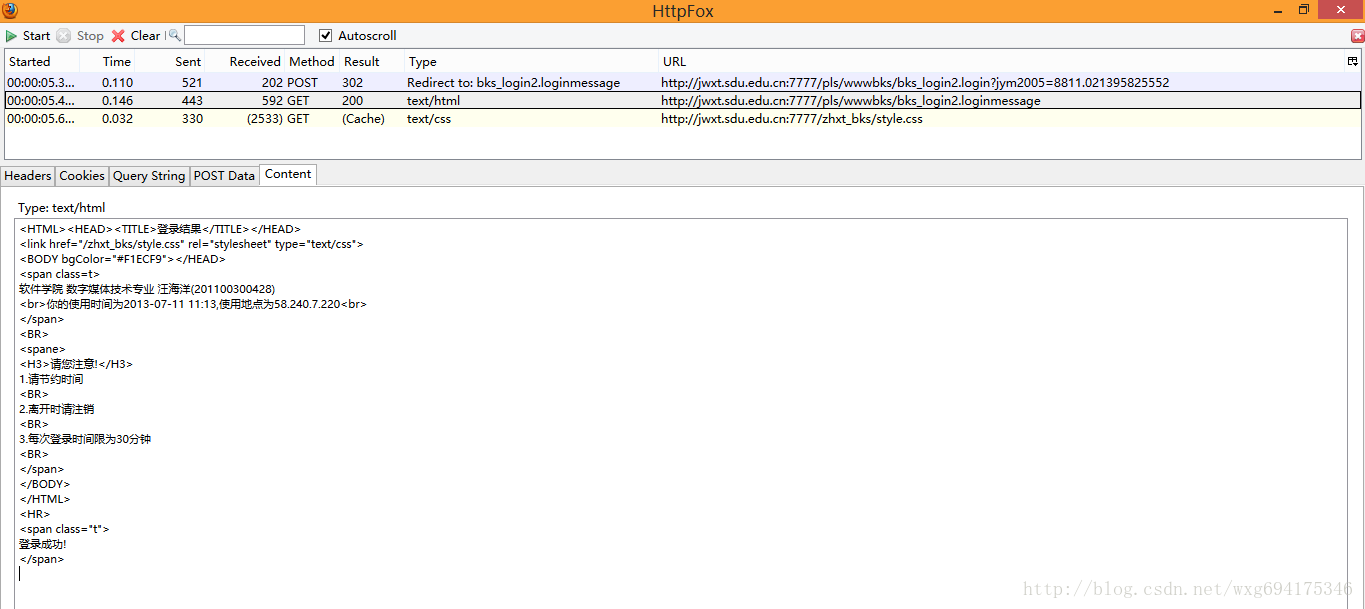
看来这个只是显示页面的html源码而已,点击cookie,查看cookie的相关信息:
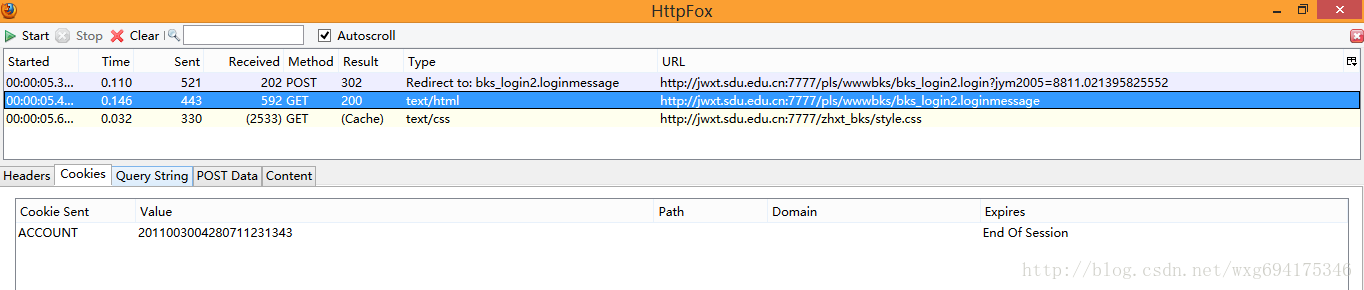
啊哈,原来html页面的内容是发送了cookie信息之后才接受到的。
再来看看最后一个接收到的信息:
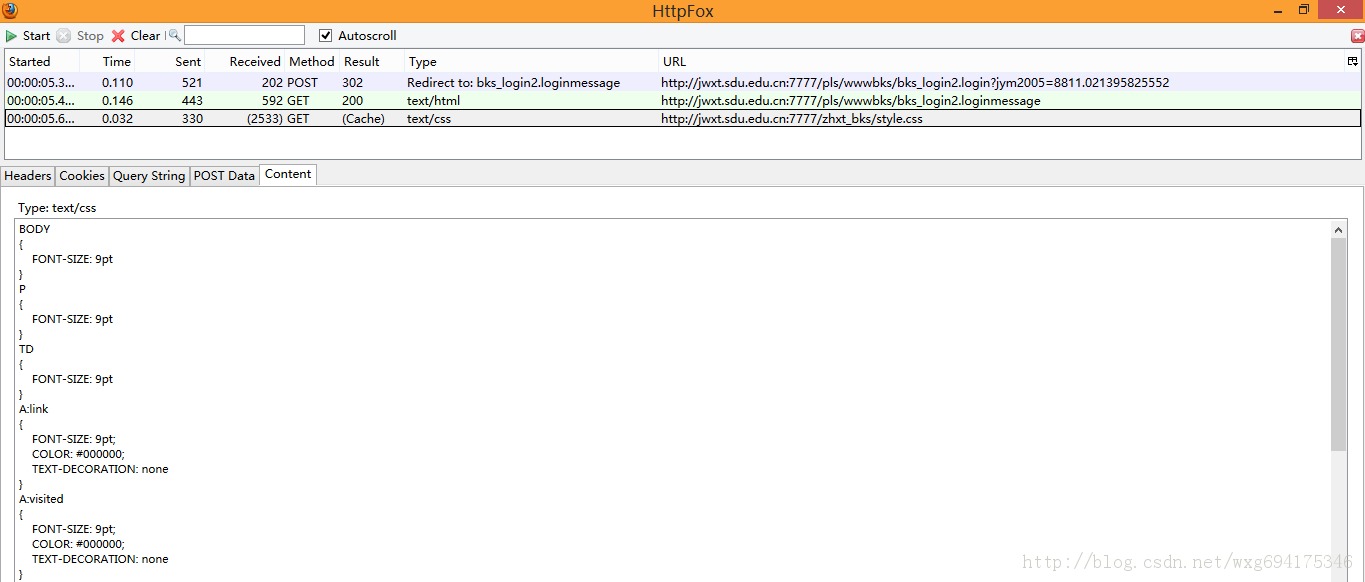
大致看了一下应该只是一个叫做style.css的css文件,对我们没有太大的作用。
4.冷静应战
既然已经知道了我们向服务器发送了什么数据,也知道了我们接收到了什么数据,基本的流程如下:
首先,我们POST学号和密码--->然后返回cookie的值然后发送cookie给服务器--->返回页面信息。获取到成绩页面的数据,用正则表达式将成绩和学分单独取出并计算加权平均数。
OK,看上去好像很简单的样纸。那下面我们就来试试看吧。
但是在实验之前,还有一个问题没有解决,就是POST的数据到底发送到了哪里?
再来看一下当初的页面:

很明显是用一个html框架来实现的,也就是说,我们在地址栏看到的地址并不是右边提交表单的地址。
那么怎样才能获得真正的地址-。-右击查看页面源代码:
嗯没错,那个name="w_right"的就是我们要的登录页面。
网站的原来的地址是:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html
所以,真正的表单提交的地址应该是:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/xk_login.html
输入一看,果不其然:
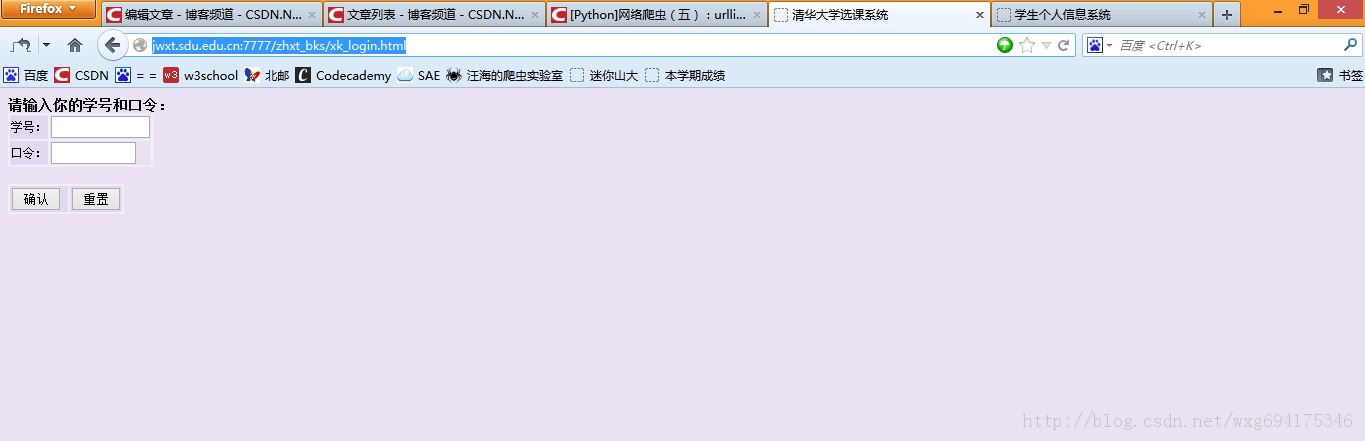
靠居然是清华大学的选课系统。。。目测是我校懒得做页面了就直接借了。。结果连标题都不改一下。。。
但是这个页面依旧不是我们需要的页面,因为我们的POST数据提交到的页面,应该是表单form的ACTION中提交到的页面。
也就是说,我们需要查看源码,来知道POST数据到底发送到了哪里:
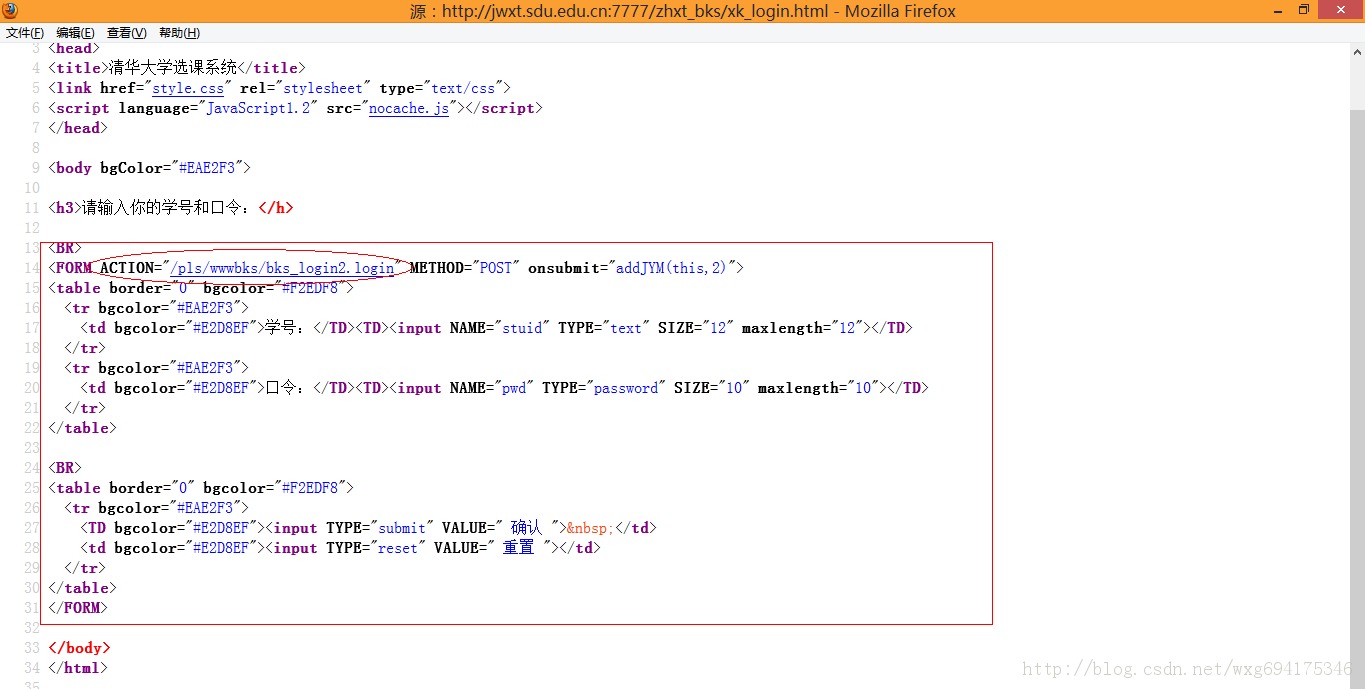
嗯,目测这个才是提交POST数据的地址。
整理到地址栏中,完整的地址应该如下:
http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login
(获取的方式很简单,在火狐浏览器中直接点击那个链接就能看到这个链接的地址了)
5.小试牛刀
接下来的任务就是:用python模拟发送一个POST的数据并取到返回的cookie值。
关于cookie的操作可以看看这篇博文:




