
零基础写Java知乎爬虫之进阶篇
说到爬虫,使用Java本身自带的URLConnection可以实现一些基本的抓取页面的功能,但是对于一些比较高级的功能,比如重定向的处理,HTML标记的去除,仅仅使用URLConnection还是不够的。
在这里我们可以使用HttpClient这个第三方jar包。
接下来我们使用HttpClient简单的写一个爬去百度的Demo:
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.commons.httpclient.methods.GetMethod;
/**
*
* @author CallMeWhy
*
*/
public class Spider {
private static HttpClient httpClient = new HttpClient();
/**
* @param path
* 目标网页的链接
* @return 返回布尔值,表示是否正常下载目标页面
* @throws Exception
* 读取网页流或写入本地文件流的IO异常
*/
public static boolean downloadPage(String path) throws Exception {
// 定义输入输出流
InputStream input = null;
OutputStream output = null;
// 得到 post 方法
GetMethod getMethod = new GetMethod(path);
// 执行,返回状态码
int statusCode = httpClient.executeMethod(getMethod);
// 针对状态码进行处理
// 简单起见,只处理返回值为 200 的状态码
if (statusCode == HttpStatus.SC_OK) {
input = getMethod.getResponseBodyAsStream();
// 通过对URL的得到文件名
String filename = path.substring(path.lastIndexOf('/') + 1)
+ ".html";
// 获得文件输出流
output = new FileOutputStream(filename);
// 输出到文件
int tempByte = -1;
while ((tempByte = input.read()) > 0) {
output.write(tempByte);
}
// 关闭输入流
if (input != null) {
input.close();
}
// 关闭输出流
if (output != null) {
output.close();
}
return true;
}
return false;
}
public static void main(String[] args) {
try {
// 抓取百度首页,输出
Spider.downloadPage("http://www.baidu.com");
} catch (Exception e) {
e.printStackTrace();
}
}
}
但是这样基本的爬虫是不能满足各色各样的爬虫需求的。
先来介绍宽度优先爬虫。
宽度优先相信大家都不陌生,简单说来可以这样理解宽度优先爬虫。
我们把互联网看作一张超级大的有向图,每一个网页上的链接都是一个有向边,每一个文件或没有链接的纯页面则是图中的终点:
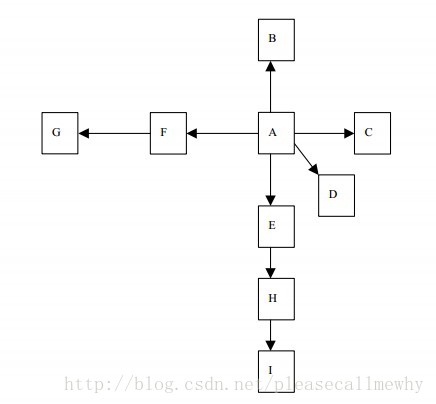
宽度优先爬虫就是这样一个爬虫,爬走在这个有向图上,从根节点开始一层一层往外爬取新的节点的数据。
宽度遍历算法如下所示:
(1) 顶点 V 入队列。
(2) 当队列非空时继续执行,否则算法为空。
(3) 出队列,获得队头节点 V,访问顶点 V 并标记 V 已经被访问。
(4) 查找顶点 V 的第一个邻接顶点 col。
(5) 若 V 的邻接顶点 col 未被访问过,则 col 进队列。
(6) 继续查找 V 的其他邻接顶点 col,转到步骤(5),若 V 的所有邻接顶点都已经被访问过,则转到步骤(2)。
按照宽度遍历算法,上图的遍历顺序为:A->B->C->D->E->F->H->G->I,这样一层一层的遍历下去。
而宽度优先爬虫其实爬取的是一系列的种子节点,和图的遍历基本相同。
我们可以把需要爬取页面的URL都放在一个TODO表中,将已经访问的页面放在一个Visited表中:
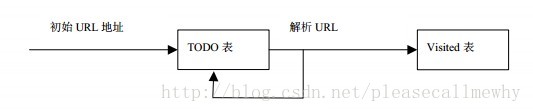
则宽度优先爬虫的基本流程如下:
(1) 把解析出的链接和 Visited 表中的链接进行比较,若 Visited 表中不存在此链接, 表示其未被访问过。
(2) 把链接放入 TODO 表中。
(3) 处理完毕后,从 TODO 表中取得一条链接,直接放入 Visited 表中。
(4) 针对这个链接所表示的网页,继续上述过程。如此循环往复。
下面我们就来一步一步制作一个宽度优先的爬虫。



