
零基础写Java知乎爬虫之进阶篇(4)
最后我们来写个爬虫类调用前面的封装类和函数: package controller; import java.util.Set; import model.LinkFilter; import model.SpiderQueue; public class BfsSpider { /** * 使用种子
最后我们来写个爬虫类调用前面的封装类和函数:
package controller;
import java.util.Set;
import model.LinkFilter;
import model.SpiderQueue;
public class BfsSpider {
/**
* 使用种子初始化URL队列
*/
private void initCrawlerWithSeeds(String[] seeds) {
for (int i = 0; i < seeds.length; i++)
SpiderQueue.addUnvisitedUrl(seeds[i]);
}
// 定义过滤器,提取以 http://www.xxxx.com开头的链接
public void crawling(String[] seeds) {
LinkFilter filter = new LinkFilter() {
public boolean accept(String url) {
if (url.startsWith("http://www.baidu.com"))
return true;
else
return false;
}
};
// 初始化 URL 队列
initCrawlerWithSeeds(seeds);
// 循环条件:待抓取的链接不空且抓取的网页不多于 1000
while (!SpiderQueue.unVisitedUrlsEmpty()
&& SpiderQueue.getVisitedUrlNum() <= 1000) {
// 队头 URL 出队列
String visitUrl = (String) SpiderQueue.unVisitedUrlDeQueue();
if (visitUrl == null)
continue;
DownTool downLoader = new DownTool();
// 下载网页
downLoader.downloadFile(visitUrl);
// 该 URL 放入已访问的 URL 中
SpiderQueue.addVisitedUrl(visitUrl);
// 提取出下载网页中的 URL
Set<String> links = HtmlParserTool.extracLinks(visitUrl, filter);
// 新的未访问的 URL 入队
for (String link : links) {
SpiderQueue.addUnvisitedUrl(link);
}
}
}
// main 方法入口
public static void main(String[] args) {
BfsSpider crawler = new BfsSpider();
crawler.crawling(new String[] { "http://www.baidu.com" });
}
}
运行可以看到,爬虫已经把百度网页下所有的页面都抓取出来了:
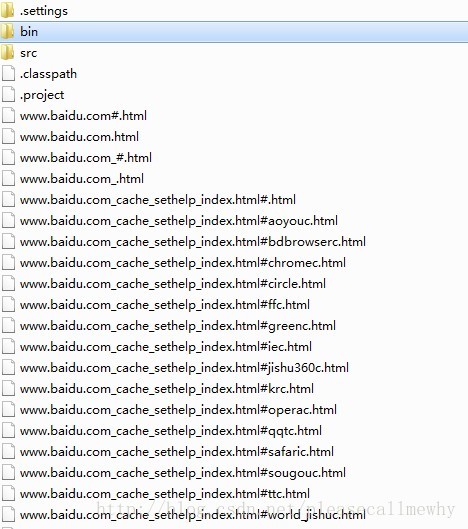
以上就是java使用HttpClient工具包和宽度爬虫进行抓取内容的操作的全部内容,稍微复杂点,小伙伴们要仔细琢磨下哦,希望对大家能有所帮助
收藏文章
精彩图集




精彩文章